
AI has a Data Problem, Firms in the Global South Are Solving It

When Meta tried to inconspicuously roll out plans to use posts, photos and captions of its ~3.98 million users to train its AI models it created an uproar.

The outrage is rightful, given the cumbersome opt-out process in place. I, for one, am comforted by Meta’s pause on the plan (as temporary as the respite may be).
While the privacy problem may be parked for now, this was a symptom of another problem - missing datasets.
And the concerns go beyond privacy. At the Munich Cyber Security Conference, one of the issues raised was how bias in AI models was due to limited training data from African regions.
Synthetic Data? Maybe.
Microsoft, OpenAI and Cohere are reportedly already testing the use of synthetic data i.e. computer-generated information to train models. Last year, Sam Altman was quoted saying he was “pretty confident that soon all data will be synthetic data”.
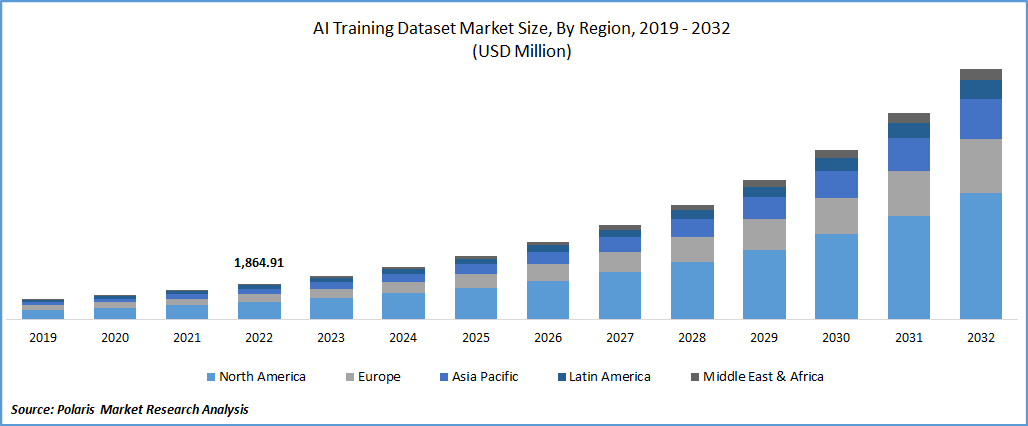
For now, though, the AI training dataset market appears to be booming.
As per a market research firm, “The global AI training dataset market size and share was valued at $2260.27 million in 2023 and is expected to grow at a CAGR of 21.5% during the forecast period.”
Just providing datasets isn’t enough. These datasets need to be diverse, accurate, and ethically sourced to truly address the problem. Now, that’s where some have spotted an opportunity.
In India, Karya’s unique model of ethical data collection is filling the gap between big tech and rural India. The company ensures that lower-resourced Indian languages find reasonable representation in training models. As a social enterprise and tech company, on the face of it, Karya’s model is not only replicable but plausibly the most ethical one out there.
In Qatar, projects like Fanar are working to collect, curate, filter and process high-quality Arabic datasets.
At the Technology Innovation Institute in Abu Dhabi, an Arabic natural language processing model NOOR was created using what was claimed to be the world’s largest high-quality cross-domain Arabic dataset.
Others like French start-up Isahit train and work with women in Africa to provide high-quality datasets.
The dataset problem is significant enough for a dedicated fund to have been set up to address it.
Lacuna Fund provides resources for locally produced and owned high-quality datasets in low-and-middle-income contexts. A perusal of their website indicates it has funded an array of projects over the past four years spanning from climate, forests, and agriculture to sexual, reproductive, and maternal health. Lacuna Fund has invested 54 countries, with a majority of the projects being run in Uganda, Kenya, Nigeria and Tanzania.
Data collection is crucial to ensure AI models can be deployed in areas with diverse demographics and different languages. But the plight of data enrichment workers is a reason to remain vigilant.
In the not-so-long history of AI models, we’ve already seen the mistreatment of data enrichment workers. Like this: OpenAI Used Kenyan Workers on Less Than $2 Per Hour. And this: The Low-Paid Humans Behind AI’s Smarts Ask Biden to Free Them From ‘Modern Day Slavery’. And this: The Hidden Workforce That Helped Filter Violence and Abuse Out of ChatGPT
For many start-ups in the Global South, building better datasets means building the foundation for better AI models in the future, and uplifting the local community in the present.